![[-]](/moniwiki/imgs/plugin/arrup.png "[-]")
![[+]](/moniwiki/imgs/plugin/arrdown.png "[+]")
[edit]
1 로컬 수평/수직 분할의 요약 #
커뮤니티의 질문 게시판에 가보면 테이블의 분할에 대한 질문이 올라오곤 한다. 또한 데이터가 쌓임으로 해서 성능이 느려졌다고 판단한 관리자들이 테이블의 분할을 고려한다. 또한 많은 사이트에서 테이블을 이미 분할하여 사용하기도 한다. 그러나 정작 테이블 분할을 단지 ‘분할을 하면 빠를 것 같아서’ 라는 애매한 이유를 이야기 할 뿐 구체적인 판단의 근거를 제시하지 못하는 경우가 대부분이다. DBMS는 총 Row수가 100건 중 1건을 가져오는 것이나 1000만 건 중 1건을 가져오는 것이나 비슷한 시간을 가지게 설계되었다. 이러한 설계는 인덱스에 기반을 두고 있다. 1000만 건 중 1건이나 100건 중 1건이나 처리하는 시간이 비슷하다면 왜 테이블 분할을 고려할까? 먼저 수직분할에 대해서 알아보자.
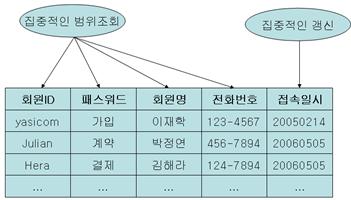
* 그림의 데이터가 문맥상 좀 이상한데, 그냥 넘어가자. 다시 그리기 귀찮다.
위의 그림을 보면 테이블에서 회원ID, 패스워드, 회원명, 전화번호에 대해서 집중적인 범위 조회가 일어나고, 접속일시는 집중적인 갱신 트랜잭션이 발생한다고 가정해 보자. 만약 회원ID가 yasicom인 회원의 접속일시를 ‘20060505’로 갱신한다면 해당 Row에 대해 Lock이 걸리게 된다. 그러면 yasicom을 포함하는 범위조회는 Lock이 풀릴 때까지 대기를 해야 한다. 또한 읽는 동안의 일관성을 보장해야 하므로 또한 갱신 트랜잭션도 대기를 해야 하는 상황이 발생할 수 있다. 이러한 경우라면 성능에 매우 큰 지장을 주므로 수직분할을 하는 것이 바람직하다. 아래의 그림은 수직분할의 예이다.
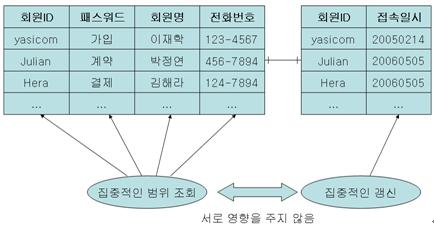
일반적으로 수평분할을 고려하는 것은 데이터가 1억 건을 넘을 경우 수평분할을 고려해야 한다고 말한다. 물론 이것도 상대적이다. 컬럼의 수가 많다면 더 적은 Row수에도 수평분할을 고려해야 한다. 데이터베이스가 대용량이라면 고려해야 할 것들이 매우 많이 있다. 예를 들면 인덱스의 재생성 시간이 길어지고, 병렬처리 및 백업/복원 전략도 틀려지게 된다. 트랜잭션에 대한 고려가 있어야 한다. MS SQL Server의 경우 Row에 4861[1]개 이상의 잠금(Lock)이 걸리면 잠금의 수준이 높아지고, 다른 트랜잭션은 대기(블록킹)하게 된다. 실제로 Lock은 데이터의 일관성을 보장하기 위해 꼭 필요한 것이다. 블록킹 자체가 문제는 아니나 그로인해 작업이 Queue에 쌓이게 되어, Lock이 풀리게 되면 한 번에 많은 양의 작업을 처리해야 하므로 부하를 주는 것과 블록킹에 의해서 응답시간이 길어지는 것이 문제다.
가장 기본적인 수평분할의 이유는 Index Depth 문제 때문이다. Row수가 많아지게 되면 인덱스를 이용하여 1건을 접근하기 위해서는 Root Node에서 Leaf Node까지의 거리가 멀어[2]진다. 즉, A라는 테이블에 Row가 100건일 경우는 2Page(or Block)을 읽었지만, 1천 만 건일 경우는 1건을 접근하기 위해서 2Page(or Block) 이상을 접근해야만 한다는 것이다. 예를 들어, 5Page를 읽고, 하루에 약 10,000번 호출되는 ProcA가 있다고 가정하자. 데이터의 증가로 ProcA가 10Page를 읽었다면, 전체적인 I/O의 양은 2배가 된다. 단순히 2배가 문제는 아니다. 서버 자원이 병목없이 처리 할 수 있는 양이라면 문제될 것은 없다. 그러나 어느 한 곳에 병목이 발생하기 시작하면 서버의 처리량은 급감하게 된다. 콜레스테롤이 조금씩 쌓여 동맥경화를 일으켜 사망하게 하는 것과 같다. (조금 막혔을 뿐인데..) 하지만 여기서 불평불만을 늘어 놓아서는 안 된다. 이러한 것을 예상하지 못한 것은 애초에 이걸 고려하지 않고 용량설계한 니 잘못이기 때문이다.
많은 관리자들이 테이블의 분할을 너무 쉽게 생각하는 경향이 있다. 테이블을 분할하면 처리과정이 복잡해지는 것은 당연하다. SQL Server에서는 분할 뷰와 같은 것을 쓰면 복잡해지지 않는다고 하는 사람들도 있다. 하지만 절대 아니다. 반드시 복잡해진다. 실행계획이 꼬이는 경우도 다반사다. 또한 중복된 데이터를 가지고 있어야 하는지 중복된 데이터를 가지고 있어야 하는지에 대한 고려도 필요하다. 분할을 할 때는 반드시 타당한 근거를 제시해야 하며, 단순히 빨라질 것이라는 예상으로 수평분할을 하게 되면 많은 사람이 고생하게 되므로 충분한 고려를 해야 한다.
[edit]
2 일반적인 고려사항 #
테이블을 수평으로 분할하건 수직으로 분할하건 관리자는 성능이 떨어지면 한 번쯤은 분할을 고려해보는 경향이 있다. 그래서 필자가 왜 분할하려고 하는지 물어보면 대부분의 관리자들은 그렇게 하면 빠를 것 같다고 한다. 이것은 분할의 이유가 되지 않는다. 분할을 하려면 당연히 그에 정당한 이유가 있어야 한다. 분할을 함으로써 얻는 이점도 있기는 하지만 무턱대고 분할을 하면 손해 보는 경우가 많이 있다. (손해를 보는지도 모른다. 알면 손해를 안보지.) 분산데이터베이스를 설계하려면 다음과 같은 사항을 고려해야 한다.
- 데이터베이스 설계
- 데이터와 프로그램의 배분
- 네트워크 자체와 설계
- 공유의 정도
- 완전 독립
- 데이터의 공유(프로그램은 각각 중복되게 보관한다)
- 데이터와 프로그램의 공유
- 완전 독립
- 데이터 사용패턴
- 사용자의 사용방식이 일정: 설계가 용이
- 사용자의 사용방식이 가변
- 사용자의 사용방식이 일정: 설계가 용이
- 데이터 사용패턴에 대한 설계자의 인지도
- 정보가 없는 경우
- 필요한 모든 정보를 가진 경우
- 정보가 없는 경우
- 동기종 분산데이타베이스 설계의 경우는 중앙 집중 데이터베이스 설계와 같은 과정을 거치고 마지막 단계에서 분산을 고려한다.
- 이기종 또는 복합 데이터베이스 설계의 경우는 이미 존재하는 설계 작업이 필요하다
- 될수 있는한 기존의 데이터베이스에는 변화를 가하지 않고 전체 스키마를 통합한다.
- 조직 전업무 지원에 필요한 요구사항 정의 및 분석
- 전역 ERD작성
- 각 지역 스키마의 지역 ERD 작성
- 여러 지역 스키마간의 동의어 또는 모순 조정
- 여러 지역 스키마 간의 엔티티와 애트리뷰트의 수정 및 일치, 각 지역 엔티티, 애트리뷰트는 전역 엔티티, 애트리뷰트와 일치하여야 한다..
- 주요 트랜잭션 중심으로 분할과 배치의 비용-효과 분석
- 효과가 큰 경우 각 지역에 배치
[edit]
3 분산데이터베이스 설계의 주요 논점 #
분산데이터베이스를 설계하는데 가장 중요한 것은 왜 분산을 하는가이다. 대부분은 성능에 관련된 이슈이다. 자르면 성능이 향상된다는 막연한 기대는 버려야 한다. 분산 데이터베이스로 가는데 손익분기점을 정확히 체크해야 한다. 분할을 하게 되면 분산 트랜잭션에 대한 고민도 해야한다. 분할을 하므로써 응용 프로그램도 함께 분할되어야 하는 경우도 있다. 데이터베이스의 생명은 무결성에 있는 것이나 마찬가지이다. 데이터의 무결성이 보장되지 않는다면 좋은 정보가 산출되기는 기대하기 어렵다. 데이터 무결성의 단위는 테이블로 이루어지기 때문에 분할을 하게되면 무결성을 보장하기가 어려워 질 수도 있다.
- 어떻게 분할하는가?
- 수평분할? 수직분할?
- 어떻게 배치하는가?
- 데이터 중복의 장단점
[edit]
4 어떻게 분할하는가? #
데이터 분할을 할 때는 완전성, 재구축성을 보장해야 한다. 즉, 원래의 테이블에 있는 데이터는 분할된 어느 곳에건 반드시 있어야 하고, 분할된 데이터를 합치면 반드시 분할 이전의 모습을 갖춰야 한다는 뜻이다. 수평분할에 있어서는 모든 데이터가, 수직 분할에 있어서는 기본키를 제외한 데이터가 중복이 없어야 한다.
데이터의 중복을 고려할 경우는 특정 사이트가 다운이 되었어도 데이터가 다른 곳에 있으므로 서비스를 계속할 수 있다는 장점이 있고, 지역적으로 가까운 곳으로 접근을 하므로 빠른 응답을 보장할 수 있다. 그러나 데이터의 중복으로 인한 저장공간이 더 필요하고, 갱신비용이 더 들어간다. 그러므로 이러한 중복은 읽기전용의 데이터베이스에 적합하다.
[edit]
5 수평분할 #
수평분할의 경우 다음과 같은 장점을 가진다.
- 효율성
- 지역의 최적화
- 보안 향상
- 지역적인 접근 속도 불일치
- 복사의 취약성
[edit]
6 수직분할 #
수직분할은 수평분할에 비해 복잡하며, 응용프로그램에 따라 컬럼을 그룹핑하는 방법과 분열하는 방법이 있다. 수직분할된 테이블은 원 테이블을 프로젝션을 통해 얻을 수 있고, 역으로 원 테이블은 분할된 테이블을 조인을 통해 얻을 수 있다. 수직분할의 이점과 단점은 수평분할과 같다. 수평분할은 지역적으로 조직기능이 중복되었을 경우에 적용하고, 수직분할은 서로 다른 데이터 요구사항을 가진 조직 기능간에 적용하는 것이 보통이다.
[edit]
7 배치방법 #
배치방법은 중복배치 방법과 비중복 배치방법이다. 중복배치는 방법은 모든 지역을 대상으로 배치하는 방법과 일부만을 중복하는 방법이 있다. 비중복 배치방법도 비슷하다. 모든 트랜잭션을 대상으로 하는가 주요 트랜잭션을 대상으로 Top-Down방식으로 배치를 하느냐이다. 다음은 그 방법에 대한 정리이다.
- 비중복 배치
- 모든 트랜잭션 분석 방법: 각 배치 방법에 따라 모든 트랜젝션의 응답시간을 계산, 종합하여 응답시간이 가장 짧은 지역에 배치
- 주요 트랜잭션 분석 방법: 각 배치 방법에 따라 주요 트랜잭션의 응답시간만 종합하여 응답시간이 가장 짧은 지역에 배치
- 모든 트랜잭션 분석 방법: 각 배치 방법에 따라 모든 트랜젝션의 응답시간을 계산, 종합하여 응답시간이 가장 짧은 지역에 배치
- 중복 배치
- 모든 효과지역에 배치 방법: 우선 아무것도 없는 상태 또는 중복없이 배치된 상태에서 시작하여 각 주어진 지역에 배치하는 효과가 비용보다 클 경우 배치
- 최대 효과지역 배치 방법: 중복이 없는 상태로 배치한 후 가장 효과가 큰 중복을 차례로 배치하여 효과가 있는 중복이 없을 때 가지 계속한다.
- 모든 효과지역에 배치 방법: 우선 아무것도 없는 상태 또는 중복없이 배치된 상태에서 시작하여 각 주어진 지역에 배치하는 효과가 비용보다 클 경우 배치