![[-]](/moniwiki/imgs/plugin/arrup.png "[-]")
![[+]](/moniwiki/imgs/plugin/arrdown.png "[+]")
[edit]
1 튜닝의 필요성 #
이번 장에서는 튜닝의 절차에 대한 절차를 간략하게 알아볼 것이다. 튜닝의 절차가 필요한 것은 당연히 성공리에 튜닝을 마치기 위함이다. 각각의 항목을 살펴보면서 왜 각각의 단계가 필요한지 알아볼 것이다. 많은 컨설턴트들이 필자와 비슷한 프로세스를 밟아가며, 튜닝작업을 한다. 상황에 따라 적절히 응용하면 된다. 혹자는 이와 같은 과정은 필요 없고 “당장 이 SQL을 3초 안에 끝나게 해놔!” 라고 할 수 있다. 이 사람은 중요한 것을 잊고 있음이 분명하다. 특정 부분을 튜닝한다고 해서 무조건 빨라지고, 최적화되는 것은 아니다. 또한 특정한 부분을 튜닝하면 다른 곳이 느려질 수도 있다. 티끌들과 바위 덩어리들이 모여 태산이 된 것이므로 하나씩 잡아가는 것이 좋다. 미리 언급하지만 티끌들은 인덱스 생성 및 조정으로 거의 해결되고, 바위 덩어리들은 어루만져 줄 손이 필요하다. 다음의 그림을 보자.
이 모든 것이 만족되려면 시스템 전체를 보아야 하기 때문에 큰 그림을 그려가면서 세부적으로 들어가야 한다. 일련의 과정들은 처음 접하는 시스템을 알고 또한 효율적인 튜닝을 위함이기도 하다.
[edit]
2 적절한 권한의 획득과 협력의 약속 #
튜닝을 할 때는 많은 인력이 투입되지 않는 것이 일반적이다. 그러므로 개발자들과의 협력과 적절한 권한이 주어져야만 튜닝작업을 성공리에 마칠 수 있다. 대부분의 튜닝작업은 소스의 수정이 불가피한 경우가 많이 있으며, 소스 수정을 위해 개발자들을 통제할 수 있는 권한이 주어짐으로 해서 비용과 효과를 절감할 수 있다. 또한 튜닝인력이 모두 수정을 할 수 없으므로 교육을 통한 개발자 스스로 수정을 하도록 유도하는 것도 하나의 방법이다.
실제로 자신의 직급이나 개발자의 자존심 때문에 튜닝작업이 제대로 이루지지 않을 수도 있다. 그러므로 튜닝작업을 원만하게 진행하기 위해서 자신이 어떤 작업을 할 것이니 따라줄 것을 미리 약속 받는 것은 매우 중요하다. 우스운 것은 개발환경에 따라서 DBA의 권한이 차이가 난다는 것이다. 권한이 유닉스계열은 매우 막간한데 비해 MS계열은 DBA의 권한이 그저 그렇다. 물론 모두가 그렇지는 않지만 대략 그렇다. 개발환경이 문제는 아닐 것이다. DBA가 프로젝트의 실패가 눈에 보이지 않아서 즉, 실력이 부족였거나 DBA보다 더 막강한 권한을 지닌자가 프로젝트를 망쳐 놓았을지도..
DBA는 데이터베이스의 모든 업무를 관장하는 사람이다. 데이터베이스 시스템의 설정에서부터 설계/구현 등의 개발에 이르기까지 매우 광범위한 역할을 가지고 있다. 우리나라의 DBA라고 하면 자격증을 취득하고, 전산실에서 백업과 복원/복구를 위해 테이프를 갈아 끼우는 사람 정도로만 생각하는 경우가 많이 있다. 실제로 그런 경우가 많이 있고, 백업/복원을 하지 못하는 DBA도 있다. 심지어는 ‘SELECT * FROM TABLE_NAME’ 의 SQL만 알고 있는 경우도 있다. DBA라는 타이틀을 가지고 있으면서 직접 관리하지 않고, 다른 업체에 유지/보수 계약을 하는 경우도 많이 있다. 기업의 의사결정권자의 관점에서 보면 이중으로 돈 낭비를 하고 있는 셈이다.
그렇다면 백업을 잘 받는 사람이 DBA일까? 서적 중에는 관리자용, 개발자용이라고 해서 책을 2권으로 나누어 놓은 경우도 있고, ‘관리자의 입장에서…’ 또는 ‘개발자의 입장에서…’라는 말을 쓰기도 한다. (물론 필자의 또 다른 책에서 ‘관리자를 위한’ 이라는 단어가 붙어 있다. 필자는 상당히 맘에 들지 않았지만 대세였기에 따르는 것이 낫겠다는 생각을 그 당시에는 그렇게 했다.) 과연 개발자, 관리자로 나눌 필요가 있을까? 그렇다면 DBA는 무엇일까? 말 그대로 DBA는 데이터베이스에 관련된 모든 업무를 능숙하게 할 수 있는 사람이라고 할 수 있다. 프로그램 소스도 어느 정도 볼 줄 알아야 하고, 쿼리 작성 능력과 성능 튜닝에 대한 능력도 갖추어야 한다. 또한 데이터베이스 서버의 운영과 데이터베이스 모델링과 설계에 대한 능력도 갖추어야 한다. 결국 데이터베이스 관리와 데이터베이스 개발은 동의어로 봐야 할 것은 당연하다.
또 한가지 고려해야 할 것은 자체개발인지 아니면 아웃소싱인지를 알아야 한다. 외부업체에서 개발한 환경이라면 소스 수정이 가능한지에 대한 우선적인 확인이 필요하다. 어플리케이션 튜닝은 대부분 소스 수정을 유발하기 때문이다.
[edit]
3 기업의 시스템 환경 파악 및 자료 수집 #
기업의 시스템 환경을 파악하는 것이 튜닝의 첫 번째 단계라고 할 수 있다. 어떤 OS를 사용하고 있으며, 패치는 어디까지 적용되었는지 또는 Storage RAID 레벨 등의 하드웨어 스펙을 파악하는 단계이다. Windows 시스템에서는 “성능” 도구를 이용한다. 다음은 모니터링에 필요한 정보들이다. “Processor Time <= 80%” 의 의미는 평균 80% 이하여야만 정상이라고 판단할 수 있다는 것이다. 물론 피크타임이 업무에 매우 중요한 상황이라면 특정 시간에 기준을 맞추어야 할 것이다. 성능개체는 필요에 따라서 더 추가한다. (참고:  기본적으로 수집해야 할 데이터의 예)
기본적으로 수집해야 할 데이터의 예)
기본적으로 수집해야 할 데이터의 예)- CPU 성능(Processor 개체)
- Processor Time <= 80%
- Privileged Time <= 80%
- User Time <= 80%
- Processor Time <= 80%
- Application 성능(Process 개체)
- Processor Time <= 200%
- Processor Time <= 200%
- Memory 성능(Memory 개체)
- Available Bytes >= 5MB
- Pages/sec ---- Between 0 and 20
- Page Reads/sec <= 5
- Page Writes/sec <= 5
- Available Bytes >= 5MB
- System 성능(System 개체)
- Processor Queue Length <= 2
- Processor Queue Length <= 2
- Disk I/O 성능(PhysicalDisk 개체)
- Disk Read Time <= 40%
- Disk Write Time < 40%
- Disk Time <= 80%
- Disk Read Time <= 40%
이러한 자료 이외에 ERD, 코드규칙집, 총 사용자수, 동시 사용자수 등과 같은 이제까지의 모든 시스템 개발 결과 문서를 수집해야 한다. 일반적으로 자신의 회사가 아닌 이상에 성능튜닝을 외부업체에 맡긴다는 것 자체가 문제다. 아마도 문서를 찾기가 쉽지 않을 것이다. 문서가 존재해도 매우 옛날 것이라 큰 도움이 되지는 않을 것이다. (그래도 없는 것보다는 낫다.) 어쨌든 최대한 시스템과 관련된 모든 문서를 수집하는 것은 도움이 된다. 성능모니터링에 필요한 기준값은 각 S/W 밴더나 인터넷에 널려 있으므로 쉽게 얻을 수 있다.
[edit]
4 수집된 자료의 개괄적인 분석 #
시스템 환경 파악 단계에서는 시스템에 대한 감을 잡기 위한 자료 수집단계라고 할 수 있다. 성능 모니터링 도구를 이용하여 분석된 결과를 가지고 모든 것을 판단하는 것은 절대 해서는 안 되는 짓이다. 다음의 실례를 보자. 여러 가지 요소를 모두 고려해야 함을 나타내기 위한 예제이므로 모든 성능개체에 대한 언급은 없을 것이다. 사례를 보고 중요 자원인 CPU, Memory, Disk에 대해서 알아보도록 하겠다. 해석의 결과는 예상일 뿐이지 그렇다는 결론이 아니다. 결론을 정해놓고 답을 찾는 것은 잘못된 결과를 가져올 수 있다.
성능 모니터링 도구를 이용한 데이터 수집
해석
이 사례를 통해 중요한 몇 가지 단서를 잡을 수 있다. 물론 더 많은 성능 모니터링 개체를 살펴보아야 하겠지만 이 3가지만으로도 많은 것을 알 수 있다. 이미 언급 한데로 어플리케이션 튜닝이 필요하다는 감을 잡았다. 또한 Read율과 Write율도 얻을 수 있었다. 이 시스템은 일반적인 OLTP 시스템인데 쓰기가 약 40%라면 어플리케이션에서 쓰기 연산이 많이 발생한 것을 알 수 있다. 만약 특정일에 쓰기 작업이 많은 배치작업을 한다면 문제가 되지 않지만 평상시에도 이러한 결과를 얻었다면 문제는 있다고 보아도 된다. (이런 경우는 필자의 경험에 의하면 MSSQL Server의 Tempdb를 과도한 사용도 한 몫 단단히 하고 있는 것이 대부분이었다.) 또한 현 시스템에서 RAID Level이 적합한지를 판단할 수도 있다. 만약 이 시스템이 RAID5였다면 부적합이다. RAID5는 쓰기가 10% 이상이라면 성능저하를 가져온다. RAID 레벨이 궁금하다면 Web에서 정보를 얻거나 RAID 레벨에 대해서는 따로 다루는 장을 참고하라.
중요한 것은 "현 상황" 에서이다. 즉, 어플리케이션이 최적화되었는데도 불구하고 쓰기가 40%라면 이 조직의 업무가 쓰는 연산을 많이 하는 업무이거나, 설계의 부실로 인한 어쩔 수 없는 상황이거나 어플리케이션이 부실한 경우이다. 결국은 모든 경우의 수이지만 어플리케이션 튜닝 후에 쓰기율이 10% 이하로 떨어지거나 비슷해진다면 RAID 레벨은 잘못된 것이 아니라고 판단될 수 있다. 다시 한번 언급하지만 하드웨어는 상수이다. 상수를 건드리는 것은 최후에나 하는 일이다.
만약 성능모니터링을 전개할 수 없는 개발초기 단계라면 업무분석서를 가지고 판단해야 한다. 일반적으로 서버 구축은 H/W 밴더의 엔지니어가 와서 하게 되는데, 개발 초기단계라면 이에 대한 적절한 조정도 필요할 것이다. H/W 스펙이 서버 용량 산정에 의한 것인지도 판단해야 한다. 용량 산정의 방법은 다음의 자료를 참고하라.
| 그림1: Page reads/sec |  |
| 그림2:Page writes/sec |  |
| 그림3:Free pages |  |
해석
| Page reads/sec는 DBMS 전용 시스템이라 가정할 때에 SQL Server에서 요청에 대해 필요한 메모리를 할당한 것으로 초당 페이지의 읽기 요청 수를 의미한다. 순간 높이 올라가는 수치가 많은 것을 볼 수 있는데, 이것은 시스템의 메모리를 추가시키거나 Query 튜닝의 필요성이 있을 수도 있음을 나타낸다. 즉, 특정 어플리케이션이 많은 메모리를 요구할 수 있다는 것이다. 실제로 많은 메모리를 요구하는지, 어플리케이션을 잘못 작성한 것인지는 확인을 해보아야 한다. 메모리가 부족하거나 어플리케이션 튜닝이 필요한가는 메모리에 대한 모니터링의 결과가 필요하다. 그러나 수집된 자료로 보아서는 Memory는 충분한 것으로 보이며, Query 튜닝이 필요한 것으로 판단된다. Free Pages는 남아있는 메모리의 버퍼 수를 나타낸다. 이 값이 지속적으로 작아지거나 0이면 서버에 메모리가 작음을 나타내는데 평균 2561을 나타내고 최소가 129로 0 이상이므로 Memory는 충분(2561 * 8KB > 5MB)한 것으로 판단된다. Page writes/sec는 SQL Server에 의해 발급된 초당 물리적인 데이터베이스 페이지의 쓰기 수를 말한다. 평균의 수치로 봤을 때 읽기 수(124 / (124 + 87) * 100)는 약 58.77%이며 쓰기(87 / (124 + 87) * 100)의 경우 약 41% 이다. |
이 사례를 통해 중요한 몇 가지 단서를 잡을 수 있다. 물론 더 많은 성능 모니터링 개체를 살펴보아야 하겠지만 이 3가지만으로도 많은 것을 알 수 있다. 이미 언급 한데로 어플리케이션 튜닝이 필요하다는 감을 잡았다. 또한 Read율과 Write율도 얻을 수 있었다. 이 시스템은 일반적인 OLTP 시스템인데 쓰기가 약 40%라면 어플리케이션에서 쓰기 연산이 많이 발생한 것을 알 수 있다. 만약 특정일에 쓰기 작업이 많은 배치작업을 한다면 문제가 되지 않지만 평상시에도 이러한 결과를 얻었다면 문제는 있다고 보아도 된다. (이런 경우는 필자의 경험에 의하면 MSSQL Server의 Tempdb를 과도한 사용도 한 몫 단단히 하고 있는 것이 대부분이었다.) 또한 현 시스템에서 RAID Level이 적합한지를 판단할 수도 있다. 만약 이 시스템이 RAID5였다면 부적합이다. RAID5는 쓰기가 10% 이상이라면 성능저하를 가져온다. RAID 레벨이 궁금하다면 Web에서 정보를 얻거나 RAID 레벨에 대해서는 따로 다루는 장을 참고하라.
[edit]
5 CPU, Memory, Disk 기본적인 고려사항 #
CPU
- 커서가 자주 사용되는지 파악한다.
- 프로시저 내에서 루프를 사용하며, 루프 내에 쿼리가 있는지 파악한다.
- 적절한 인덱스가 있는지 파악한다. (병렬처리확인)
- 과도한 Hash Join이 발생하는지 파악한다.
- 과도한 정렬이 발생하는지 파악한다.
- 하드 파싱이 계속 발생하는지 파악한다.
- Blocking 및 Dead Lock이 발생하는지 파악한다.
- 적절한 인덱스가 있는지 파악한다.
- Buffer Cache Hit율이 90% 이상인지 파악한다.
- 대량의 데이터를 로드하는 작업이 있는지 파악한다. (잘못된 SQL 가능성 큼)
- Disk I/O 병목이 있는지 파악한다.
- 과도한 정렬이 발생하는지 파악한다.
- Merge Join이 자주 발생하는지 파악한다.
- Tempdb를 자주 사용하는지 파악한다. (임시테이블)
- 트랜잭션(Insert, Update, Delete)작업이 자주 발생하는지 파악한다.
- 적절한 인덱스가 있는지 파악한다.
- 로그 및 데이터 등의 객체에 대한 적절한 분산이 이루어졌는지 파악한다.
- Blocking 및 Dead Lock이 발생하는지 파악한다.
[edit]
6 DBMS Wait Event 모니터링 #
이 정도 진행되었다면 사용자의 목소리, 개발자의 목소리는 어느 정도 들었을 것이다. 이제 어떤 부분에서 병목이 있는지 파악할 필요가 있다. Microsoft 기술지원부에서는 병목지점 파악을 위한 2개의 저장 프로시저를 제공한다. 이 프로시저는 MSSQL Server의 Wait Type을 수집하는 것이다. 수집된 정보를 가지고 분석한다.
- SQL2k Wait Event 모니터링
- Oracle Wait Event 모니터링
- SQL Server 2005 Performance Tuning Waits Queues
- Troubleshooting Performance Problems in SQL Server 2005
- 스크립트1, 스크립트2를 수행시켜 2개의 저장 프로시저를 생성
- 쿼리분석기를 2개 띄우거나 쿼리분석기에서 각각 다른 세션을 가진 창을 준비
- 세션1에서 exec track_waitstats 를 수행(기본값 : 10분 수행)
- track_waitstats의 수행이 끝나면 세션2에서 exec get_waitstats을 수행하여 정보를 수집
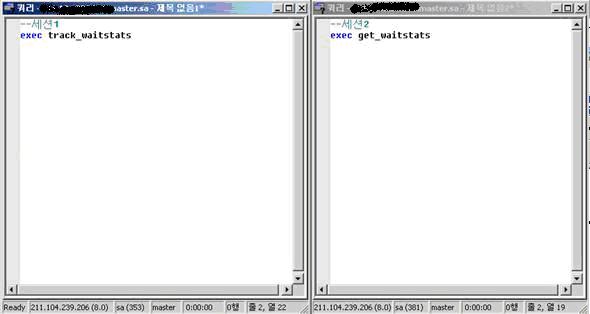
만약 정보 수집시간의 기본값인 10분이 부족하시다면 track_waitstats 프로시저의 파라미터인
@num_samples int=10의 값을 10에서 더 늘려주면 된다. 결과는 다음과 같다.
@num_samples int=10의 값을 10에서 더 늘려주면 된다. 결과는 다음과 같다.
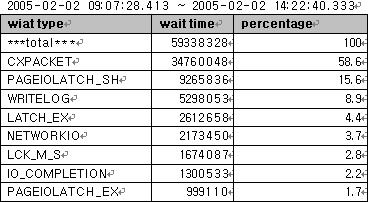
대기유형 분석'
CXPACKET
CXPACKET는 Parallel Process 대기유형이다. 이것은 Parallel Query에 실행 시 각 Process가 실행되는 구간에 Lock Issue가 있을 수도 있음을 의미하거나 특정 하드웨어의 병목으로 인해 다른 Process가 대기하고 있는 Process가 끝날 때까지 대기하고 있을 수도 있음을 의미한다. DBMS가 올바른 판단을 하여 병렬처리를 했는지 아니면 환경을 만들어주지 않아서 할 수 없이 병렬처리를 하는 것인지 잘 판단해야 한다.
PAGEIOLATCH_SH
PAGEIOLATCH_SH는 SELECT 쿼리 시 Shared Latch를 얻기 위해 대기하고 있음을 의미한다. Latch의 개념은 다음과 같다. (Disk-to-Memory transfers)
CXPACKET는 Parallel Process 대기유형이다. 이것은 Parallel Query에 실행 시 각 Process가 실행되는 구간에 Lock Issue가 있을 수도 있음을 의미하거나 특정 하드웨어의 병목으로 인해 다른 Process가 대기하고 있는 Process가 끝날 때까지 대기하고 있을 수도 있음을 의미한다. DBMS가 올바른 판단을 하여 병렬처리를 했는지 아니면 환경을 만들어주지 않아서 할 수 없이 병렬처리를 하는 것인지 잘 판단해야 한다.
PAGEIOLATCH_SH는 SELECT 쿼리 시 Shared Latch를 얻기 위해 대기하고 있음을 의미한다. Latch의 개념은 다음과 같다. (Disk-to-Memory transfers)
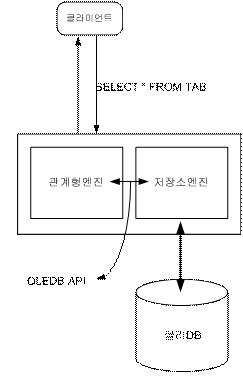
클라이언트의 요청에 따라 관계형 엔진은 OLEDB API를 이용하여 데이터의 요청을 하게 된다. 이 요청에 따라 저장소엔진은 Latch를 얻고, 관계형 엔진으로 전송한 다음 Latch를 해제한다. (메모리 보호 목적, 메모리에 캐시된 Page를 고치는 쓰레드(?)는 1개이어야 한다. 디스크에서 메모리로 데이터를 올리는 도중에 메모리의 page를 읽으면 안되기 때문에 완전히 디스크에서 메모리로 데이터를 적재하기 전까지는 다른 요청은 대기해야 한다. 이게 latch wait 이다)
WRITELOG
로그를 쓰기 위해 대기하고 있는 시간. Disk의 쓰기 성능에 직접영향을 미침. Temp Table을 생성하여 Temp Table에 Insert, Delete, Update 작업을 하거나 Table에 이러한 작업이 많이 일어난다면 병목지점이 될 수 있다.
LATCH_EX
LATCH_EX는 배타적인 LATCH를 얻기 위해 대기하는 시간
NETWORKIO
NETWORKIO는 Network Input/Output에 대기하는 시간. NIC의 Bandwidth를 체크해야 한다.
LCK_M_S
Latch를 얻은 동안에는 다른 프로세스가 페이지의 변경 등을 하지 못하도록 Lock을 걸게 되는 것이다. 그러므로 Latch를 얻고 Latch를 해제할 때까지의 시간이 빠르면 빠를수록 성능은 증가된다. 즉, Memory와 Disk간에 데이터 전송이 빠르다면 LCK_M_S, PAGEIOLATCH_SH의 대기 시간은 줄어들 것이다.
IO_COMPLETION
IO_COMPLETION는 I/O 요청을 완료하는데 대기하는 유형을 말한다. Query Plan이 나쁜 경우 발생하는 대기 유형으로 Full Scan, Index Scan이 일어나는 쿼리에 대한 Query Plan 조정이 필요하다.
PAGEIOLATCH_EX
PAGEIOLATCH_EX는 LATCH_EX 대기 유형과 함께 일어나는 대기 유형이다.
분석요약
수집된 데이터로 보아 CXPACKET, PAGEIOLATCH_SH 대기유형이 70% 이상을 차지 하고 있다. 살펴보아야 할 것은 이 시간대에 큰 작업이 일어났는지에 대한 것과 블록킹에 대한 이슈이다. 만약 실행계획이 잘못되어서 쿼리를 수행하는 총 비용이 MSSQL Server에서 설정한 값(기본값:5)보다 더 크다면 병렬쿼리를 수행할 것이다. 중요한 것은 과연 병렬쿼리가 필요한가에 대한 평가이다. 또한 Latch에 대한 대기유형도 만만치 않다. 이 의미는 두 가지로 해석해 볼 수 있다. 즉, Memory 부족이거나 Disk I/O 성능에 관련된 것이다. 물론 H/W의 관점에서만 보면 그렇다. 어플리케이션이 제대로 작성되었는지의 여부를 판단 후 Memory와 Disk I/O에 대해서 살펴보아야 할 것이다.
로그를 쓰는 것도 약 9%의 대기유형을 보였다. 트랜잭션에 대한 로그를 기록하기 위해서 프로세스가 대기한 비율이 약 9%라는 것이다. 이것으로 보아도 Disk에 뭔가 안 좋은 구성이 있을 수 있다는 감을 잡을 수 있다. 또한 Disk에 병목이 있음도 알 수 있다. 그러나 중요한 것은 어플리케이션이 최적화되었는지의 여부가 먼저 판단되어야 하는 것이다.
로그를 쓰기 위해 대기하고 있는 시간. Disk의 쓰기 성능에 직접영향을 미침. Temp Table을 생성하여 Temp Table에 Insert, Delete, Update 작업을 하거나 Table에 이러한 작업이 많이 일어난다면 병목지점이 될 수 있다.
LATCH_EX는 배타적인 LATCH를 얻기 위해 대기하는 시간
NETWORKIO는 Network Input/Output에 대기하는 시간. NIC의 Bandwidth를 체크해야 한다.
Latch를 얻은 동안에는 다른 프로세스가 페이지의 변경 등을 하지 못하도록 Lock을 걸게 되는 것이다. 그러므로 Latch를 얻고 Latch를 해제할 때까지의 시간이 빠르면 빠를수록 성능은 증가된다. 즉, Memory와 Disk간에 데이터 전송이 빠르다면 LCK_M_S, PAGEIOLATCH_SH의 대기 시간은 줄어들 것이다.
IO_COMPLETION는 I/O 요청을 완료하는데 대기하는 유형을 말한다. Query Plan이 나쁜 경우 발생하는 대기 유형으로 Full Scan, Index Scan이 일어나는 쿼리에 대한 Query Plan 조정이 필요하다.
PAGEIOLATCH_EX는 LATCH_EX 대기 유형과 함께 일어나는 대기 유형이다.
수집된 데이터로 보아 CXPACKET, PAGEIOLATCH_SH 대기유형이 70% 이상을 차지 하고 있다. 살펴보아야 할 것은 이 시간대에 큰 작업이 일어났는지에 대한 것과 블록킹에 대한 이슈이다. 만약 실행계획이 잘못되어서 쿼리를 수행하는 총 비용이 MSSQL Server에서 설정한 값(기본값:5)보다 더 크다면 병렬쿼리를 수행할 것이다. 중요한 것은 과연 병렬쿼리가 필요한가에 대한 평가이다. 또한 Latch에 대한 대기유형도 만만치 않다. 이 의미는 두 가지로 해석해 볼 수 있다. 즉, Memory 부족이거나 Disk I/O 성능에 관련된 것이다. 물론 H/W의 관점에서만 보면 그렇다. 어플리케이션이 제대로 작성되었는지의 여부를 판단 후 Memory와 Disk I/O에 대해서 살펴보아야 할 것이다.
[edit]
8 Index 분석 #
튜닝작업에 의뢰가 들어온다면 Index에 대한 최적화가 이루어졌다는 것은 기대하기 어렵다. 그러므로 어플리케이션들이 잘 수행되게 하기 위해서는 적절한 환경의 조성이 필요하다. 사용자들의 정보욕구를 만족시키기 위한 적절한 서버의 용량이 갖추어져 있어야 하며, 적절한 네트워크 대역폭등의 하드웨어 환경과 소프트웨어적인 적절한 설정이 필요하다. 그러므로 작성된 많은 Query들이 최소한의 자원을 이용하여 결과집합을 만들게 하기 위해서 적절한 인덱스의 생성이 필요하다.
인덱스 생성에는 많은 고려가 필요하다. 특정 하나의 Query를 최적화 시키기는 매우 쉽지만 여러 개의 Query가 모두 제대로 동작하게 하기 위해서는 종합적인 판단이 필요하다. 물론 이에 우선하여 인덱스에 대한 정확한 이해가 필요하다. 물론 이전에 더욱 고려되어야 하는 사항은 당연히 설계이전의 단계이다. 인덱스 설계는 논리 모델에 직접적인 영향을 미친다. 이에 대한 사례는 “설계의 중요성” 단계에서 자세히 다루기로 하겠다.
수집된 정보를 이용하여 Index 선정
각 DBMS 벤더들은 점점 사람이 할 일을 줄이고 있다. Microsoft사는 그 중 더 심하다. Oracle사도 마찬가지로 DBA의 할 일을 줄이고 있다. 그러므로 DBA의 업무는 창조적인 업무(Query, SP작성, Modeling & Design)로 이동되고 있는 추세이다. Index에 대한 것도 MS-SQL Server는 Index Tuning Wizard 라는 툴을 두어 꽤 효과적으로 Index를 선정한다. 이 툴만이라도 적당히 잘 이용하면 그나마 성능에 대한 걱정은 약간 덜 수 있다. 그러나 이 툴도 성격이 있어 나온 결과를 DBA가 확인하여 적절히 조정 후 서버에 적용해야 한다. Index Tuning Wizard를 사용하기 위해서는 자료의 수집이 매우 중요하다.
Index Tuning Wizard는 Profiler라는 툴로 수집된 자료를 이용하거나 쿼리분석기에서 특정 Query를 작성하여 이를 토대로 분석한 다음 Index에 대한 조언해 준다. 사용법은 쉬우니 매뉴얼이나 다른 참고 서적을 참고하자. Index Tuning Wizard는 주로 결합인덱스를 생성하려고 많은 노력을 기울인다. 조건 절을 해석하여 열심히 결합인덱스를 만들려고 한다. 많은 자료를 수집하여 Index Tuning Wizard를 수행하면 필요 없는 인덱스 만들어질 수도 있다는 것이다. (노파심에서 이야기 하지만 이 말은 자료를 조금 수집하라는 말이 아니다. 툴의 한계를 설명하는 것이다.) 예를 들어, 병원의 경우 ChartNo(차트번호)라는 컬럼이 대부분의 Query 조건에 속하게 된다. 경우에 따라 틀리지만 하나의 테이블에 같은 ChartNo는 1~3건 정도일 것이다. 아마도 자료를 수집하여 Index Tuning Wizard를 실행하면 다음과 같은 형태의 Index 생성을 조언할 것이다.
각 DBMS 벤더들은 점점 사람이 할 일을 줄이고 있다. Microsoft사는 그 중 더 심하다. Oracle사도 마찬가지로 DBA의 할 일을 줄이고 있다. 그러므로 DBA의 업무는 창조적인 업무(Query, SP작성, Modeling & Design)로 이동되고 있는 추세이다. Index에 대한 것도 MS-SQL Server는 Index Tuning Wizard 라는 툴을 두어 꽤 효과적으로 Index를 선정한다. 이 툴만이라도 적당히 잘 이용하면 그나마 성능에 대한 걱정은 약간 덜 수 있다. 그러나 이 툴도 성격이 있어 나온 결과를 DBA가 확인하여 적절히 조정 후 서버에 적용해야 한다. Index Tuning Wizard를 사용하기 위해서는 자료의 수집이 매우 중요하다.
ChartNo + ColA + ColB ChartNo + ColB + ColC + ColD ChartNo + ColZWhere에 명시한 조건을 모두 결합인덱스로 만들어진 격이다. (소스를 보지는 않았지만 경험상 Index Tuning Wizard는 조건 절에 명시한 컬럼과 선택도를 이용하여 Index를 생성하는 것으로 파악된다.) 위의 경우 ChartNo는 많아야 3건임에도 불구하고 ChartNo로 시작한 결합인덱스가 많이 만들어진 것을 볼 수 있다. 이러한 것은 Index Tuning Wizard 뿐만 아니라 개발자도 이러한 경향을 보이는 경우가 많이 있다. 그래서 필자와 같은 경우 Tuning 작업을 할 때 환경파악 이후 Index 정리작업부터 한다. 필요 없는 인덱스를 지워주거나 다시 작성하는 것이다. 위와 같이 인덱스가 생성되어 있을 경우는 삭제대상이다. 즉, ChartNo 컬럼에 단일 인덱스로 구성하는 것이 가장 최적이라는 것이다. 지금은 튜닝의 절차를 다루데 중점을 두고 있으므로 왜 인덱스를 생성하며, 인덱스를 조정하고, 추가하여 주어야 하는지는 인덱스 부분에서 자세히 다루도록 하겠다.
[edit]
9 데이터베이스 디자인 튜닝 #
데이터베이스 디자인 튜닝은 매우 민감한 사안이다. 정치적(?)으로도 프로젝트 전반적인 영향도도 매우 크다. 정치적이라는 표현을 쓴 것은 데이터베이스 디자인을 나이 많은 관리자급의 프로젝트 참가자가 진행하기 때문이다. 만약 디자인에 대해서 어떤 지적을 하면 대부분의 관리자들은 난감해하고, 기분 나빠하기 때문에 말에 귀를 기울이지 않는다. 의사소통이 없는 작업은 매우 힘들기 마련이다.
또한 데이터베이스 디자인 변경은 프로그램 소스의 변경을 유발하기 때문에 결합도가 강한 프로그램을 만들었다면 디자인 변경에 대한 영향은 매우 크다. 그러므로 디자인의 변경은 신중에 신중을 기해야 하고, 변경영향 분석을 반드시 해야 한다.
만약 개발 초기 단계라면 프로그램 소스에 대한 수정은 그리 많지는 않을 것이므로 변경에 대한 영향은 적다. 이러한 현상은 매우 바람직한 현상이며, 프로젝트 관리자는 매우 현명한 사람임에는 분명하다. 디자인 튜닝을 하려는 노력은 프로젝트의 개발기간을 단축하고, 좋은 질의 정보를 사용자에게 제공할 수 있는 초석이 될 것임에는 분명하다.
[edit]
10 SQL 튜닝 대상 수집 #
이 단계에서 독자들이 약간은 혼란 할 수도 있을 것이다. Index 생성 및 조정을 위한 데이터를 수집했는데 또 무얼 수집한다는 말인가? 맞는 말이다. 요는 모든 SQL을 대상으로 하되 우선시되는 것들을 먼저 분류를 하자는 것이다. 이 자료는 튜닝작업 완료 시 얼마만큼의 효과를 가진 작업이였는지 평가할 대상의 자료가 되기도 한다. 딜레마는 응답시간 또는 전체 처리시간이 많은 것부터 하느냐 아니면 자원의 사용량이 많은 것을 대상으로 하는가에 대한 문제이다. 다음은 필자가 사용하는 형식의 문서이다.
[edit]
11 Query 및 SP 최적화 #
모든 데이터가 수집되었다면 이제부터는 어플리케이션 튜닝을 하게 된다. 물론 이전에 비즈니스 로직의 튜닝이 이루어진다면 더욱 좋다. 수집된 자료를 토대로 하나씩 성능에 악영향을 끼치는 것들을 제거해 나감으로써 이 단계의 작업은 진행된다. 이 단계에서는 튜닝 작업자의 SQL 작성 능력과 관계자들의 협조가 튜닝 작업의 성공요인으로 매우 중요하게 작용한다. SQL 튜닝은 다음의 3가지 관점에서 파악된다.
SQL Tuning의 3가지 관점
- 쿼리 분석기를 통한 비용 조절
- 올바른 인덱스 사용
- 조인 순서 조정
- 힌트의 사용
- 올바른 인덱스 사용
- LOGIC 튜닝
- CASE WHEN 문
- OUTER JOIN
- 프로시저 및 함수
- CASE WHEN 문
- BATCH 작업 튜닝
- 최소 입/출력이 가능하게 조정
- LOOP내 쿼리는 최대한 튜닝
- 이용 가능한 자원을 적절히 사용하도록 조정
- 최소 입/출력이 가능하게 조정
[edit]
12 트랜잭션 정보 수집 #
Query 및 SP를 최적화 했음에도 불구하고 느린 쿼리가 있거나 응답시간이 실행시마다 틀린 것은 Blocking 및 Dead Lock을 의심해야 한다. 혹자는 데이터베이스 서버에서 어떻게 해 줄 것을 기대하고 있으나 이것은 잘못된 기대이다. 왜냐하면 트랜잭션의 주인은 어플리케이션에 있기 때문이다. 트랜잭션 문제는 99%가 어플리케이션 또는 설계의 잘못이라고 감히 말할 수 있다. (대부분은 어플리케이션) 서버에서 제어할 수 있는 것은 다만 최적의 Index를 만들어 트랜잭션의 영향을 최소화시키고, 프로세스를 Kill하거나 고립화 레벨을 조정할 수 있는 것뿐이다.
[edit]
13 하드웨어 튜닝 #
하드웨어 튜닝 전 서버 측에서 어플리케이션이 잘 돌아갈 수 있도록 환경을 만들어 준다. 예를 들어 Index 재생성 및 조각모음, Disk 조각모음과 같은 작업이다. 또한 적절한 Disk 분산으로 부하를 분산시켜주는 것이 중요하다. 모든 단계가 끝났음에도 불구하고 성능이 떨어진다면 하드웨어 자원의 부족이거나 설계상의 문제이므로 하드웨어 증설을 고려한다. 이때는 성능모니터링 도구와 MSSQL Server 병목을 모니터링 한 자료를 가지고 어떤 부분의 자원이 부족한지를 파악한 뒤 하드웨어 증설을 고려해야 한다. 중요한 것은 경험에 의한 판단을 하지 말라는 것이다. 이전에 메모리를 증설하였더니 성능이 향상되었다고 하여 성능 문제가 발생하여 또 다시 메모리를 증설하는 것은 매우 잘못된 것이다. 어느 한 곳이 병목이라면 유기적으로 묶여져 움직이기 때문에 성능이 떨어질 수 있음을 알아야 한다.
[edit]
14 처리의 우선순위 결정 #
정보시스템은 C/S[1]환경이가 n-Tier 환경이다. 예를 들어 클라이언트, 미들웨어, 데이터베이스와 같은 3단계 구조를 가지고 있다고 가정했을 때에 어느 Layer에서 처리를 하는 것이 가장 좋은지를 판단해야 한다. 미들웨어나 데이터베이스에서 구현은 가능하지만 클라이언트에서 처리하는 것이 더 바람직 할 수도 있다는 소리다. 너무 DB만을 고집하지 말고, 과감히 버릴 것은 버려라. 예를 들어 다음과 같은 형식으로 데이터를 뿌려주고 싶다는 요구사항이 있다고 가정하자. (반복되는 값을 가진 것을 첫 행만 보여주는 것)
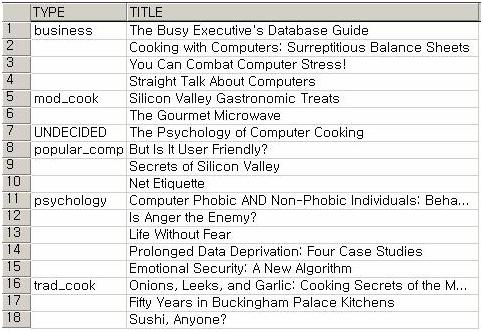
SELECT CASE WHEN FLAG = 2 THEN TYPE ELSE '' END TYPE , TITLE FROM ( SELECT MIN(CASE WHEN FLAG = 1 THEN TYPE END) TYPE , MIN(CASE WHEN FLAG = 1 THEN TITLE END) TITLE , MIN(CASE WHEN FLAG = 2 THEN FLAG END) FLAG FROM ( SELECT MIN(TYPE) TYPE , MIN(TITLE) TITLE , MIN(TITLE_ID) TITLE_ID , MIN(ID) FLAG FROM TITLES A CROSS JOIN (SELECT 1 ID UNION ALL SELECT 2) B GROUP BY CASE WHEN ID = 1 THEN TITLE_ID ELSE TYPE END ) T GROUP BY TITLE_ID ) T물론 쿼리 결과는 위에서 원하는 형태로 나왔다. 물론 다른 방식도 있다. DBMS가 오라클이라면 분석용 함수를 이용하여 간단히 해결할 수 있었을 것이다. SQL Server 2005라면 ROW_NUMBER()를 이용하면 매우 쉽다. 다만 서버 측에서 처리하기에는 (결과는 나오지만) 비효율적인 처리인 경우 무리하게 서버 처리를 고집하지 말고, 중간계층이나 클라이언트 프로그램에서 처리하도록 하는 것도 자원 사용의 분산으로 인한 성능 향상효과가 있다는 것을 알아달라는 것이다. 위 쿼리의 경우도 자원의 사용량으로 볼 때 클라이언트나 중간계층에서 처리하는 것이 더 낫다고 볼 수 있으나, 개발시간과 같은 상황 요소도 고려해야 한다.