1 준비작업 #
테스트를 위한 준비작업이다.
if object_id('test') is not null
drop table test;
go
with temp1(num)
as
(
select 1 num
union all
select num + 1 from temp1
where num + 1 <= 5000
),
temp2(num)
as
(
select 1 num
union all
select num + 1 from temp2
where num + 1 <= 600
)
select
identity(int,1,1) seq
, convert(char(8), getdate() + b.num, 112) dt
, left(newid(), 12) dumy1-- 데이터를 채워넣기 위함
, newid() dumy2-- 데이터를 채워넣기 위함
into test
from temp1 a, temp2 b
option (maxrecursion 0);
create clustered index cix_seq
on test(seq);
--테이블 'test'. 검색 수 1, 논리적 읽기 수 19738
create index nix_dt
on test(dt);
--테이블 'test'. 검색 수 1, 논리적 읽기 수 20443
2 가끔 미친짓을 하는 SQL Server, 이유를 알 수 없다? #
가끔 MSSQL Server 옵티마이저가 미친 짓을 한다. 바로 다음과 같은 예다. SQL 1, SQL 2의 실행계획과 I/O를 보라.
SQL 1
--select min(dt), count(*) from test
--결과: 20080112, 3000000
declare @dt char(8)
set @dt = '20080112'
select *
from test
where dt <= @dt
--(5000 row(s) affected)
--테이블'test'. 검색수1, 논리적읽기수20444, 물리적읽기수0, 미리읽기수0, LOB 논리적읽기수0, LOB 물리적읽기수0, LOB 미리읽기수0.
SQL 2
select *
from test
where dt <= '20080112'
--(5000 row(s) affected)
--테이블'test'. 검색수1, 논리적읽기수15336, 물리적읽기수0, 미리읽기수0, LOB 논리적읽기수0, LOB 물리적읽기수0, LOB 미리읽기수0.
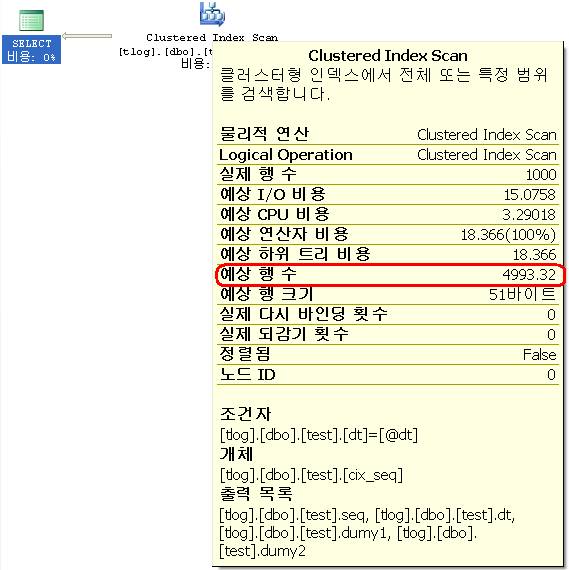
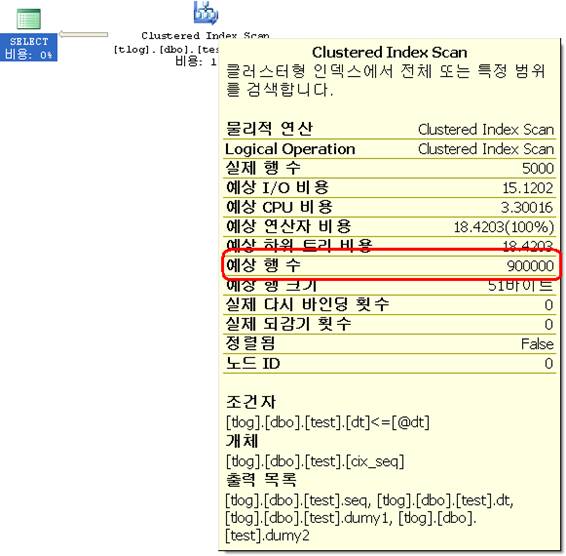
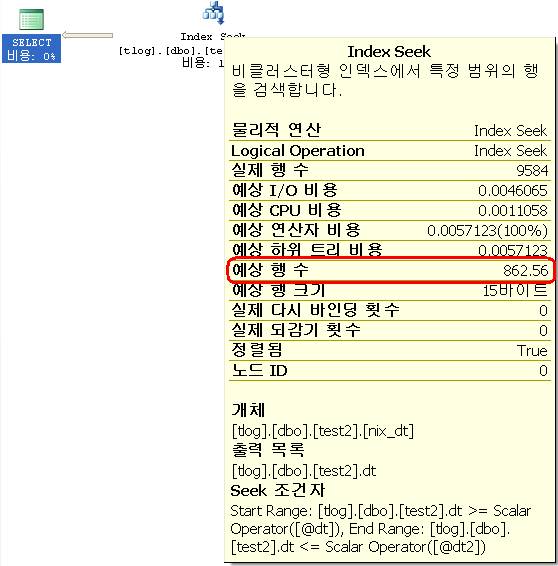
결과는 같지만 SQL 1은 풀스캔을 했으며, SQL 2는 Index Seek를 했다. 비용과 특히 ‘예상 행 수’는 많이 다른 것을 알 수 있다. 그 이유는 로컬변수를 쓴 경우인 SQL 1의 where절의 조건에 @dt이 그 이유다. 값이 결정되지 않아서 옵티마이저가 올바른 판단을 하지 못하기 때문이다. 그래도 SQL Server는 적당한 판단을 내려야 하기 때문에 SQL 1과 같이 값이 미확정적인 매개변수에 대해서 다음과 같은 기준으로 판단을 내린다. (이걸 Magic Density라고 한다. DBCC SHOW_STATISTICS의 결과는 Index Density라고 한다.)
| 조건 | 분포 |
| >, >=, <, <= | 30% |
| = | 10% |
| Between | 25% |
이 기준으로 SQL 1에서의 예상 행 수를 계산해 보면 3000000 * 0.3 = 900000 으로 딱 맞아 떨어진다. 이런 기준의 다음의 URL에서 확인할 수 있다. (아래 문서는 >, >=, <, <=의 경우는 33%로 나와 있다.)
이 문서는 SQL Server 6.0, 6.5 버전의 문서임을 감안해야 한다. 그런데 지금 필자는 2000, 2005 버전에서 테스트를 했는데 >, >=, <, <=일 경우만 유효하다. 다시 지금의 버전(2000, 2005)에 맞게 정리해보면 다음과 같다.
| 조건 | 분포 |
| >, >=, <, <= | 30% |
| = | All Density[%] |
| Between | 9% |
* All Density는 DBCC SHOW_STATISTICS의 결과에서 찾아 볼 수 있다.
3 Magic Density 테스트 #
표를 보면 알 수 있겠지만 '=' 조건이 아닌 경우는 주의를 기울여야 한다. 크기가 작은 테이블(9%이하의 액세스 범위가 Index Seek비용이 Full Scan보다 작은 테이블)의 경우 실제 액세스 범위가 넓건 좁건 간에 Index Seek를 하므로 비효율 적인 쿼리가 되기 때문이다. 그럼 ‘=’비교와 between에 대한 테스트를 해보도록 하겠다.
SQL 3
declare @dt char(8)
set @dt = '20080112'
select *
from test
where dt = @dt
--(5000 row(s) affected)
--테이블'test'. 검색수1, 논리적읽기수15336, 물리적읽기수0, 미리읽기수0, LOB 논리적읽기수0, LOB 물리적읽기수0, LOB 미리읽기수0.
SQL 4
--between테스트를위한test2 테이블만들기
select distinct * into test2
from test
insert test2
select * from test2
insert test2
select * from test2
insert test2
select * from test2
insert test2
select * from test2
go
create index nix_dt
on test2(dt)
go
--테스트
declare @dt char(8)
declare @dt2 char(8)
set @dt = '20080113'
set @dt2 = '20080114'
select *
from test2
where dt between @dt and @dt2
--(32 row(s) affected)
--테이블'test2'. 검색수1, 논리적읽기수3, 물리적읽기수0, 미리읽기수0, LOB 논리적읽기수0, LOB 물리적읽기수0, LOB 미리읽기수0.
SQL 5
--@dt2를넓게하여범위를넓혀보자
--비효율 발생!!!!
declare @dt char(8)
declare @dt2 char(8)
set @dt = '20080113'
set @dt2 = '20300114'
select *
from test2
where dt between @dt and @dt2
--(9584 row(s) affected)
--테이블'test2'. 검색수1, 논리적읽기수31, 물리적읽기수0, 미리읽기수0, LOB 논리적읽기수0, LOB 물리적읽기수0, LOB 미리읽기 수0.
--풀스캔의논리적읽기수는21
--select 862.56/9584*100 -- 9%
--@dt2의 값을 아무리 변화시켜도 예상 행 수는 변화하지 않는다.
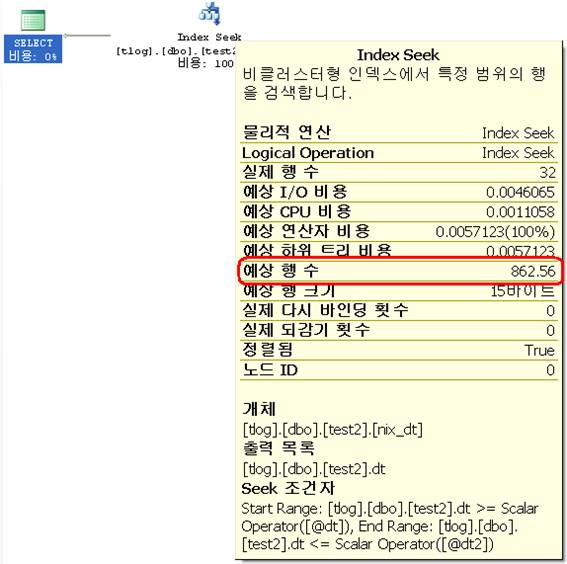
SQL3에서 인덱스를 제대로 타는 것을 볼 수 있다. 예상 행 수를 제대로 찍는 것을 보면 ‘=’ 비교의 경우는 Index Desity를 참조한다는 것을 알 수 있다. 즉,
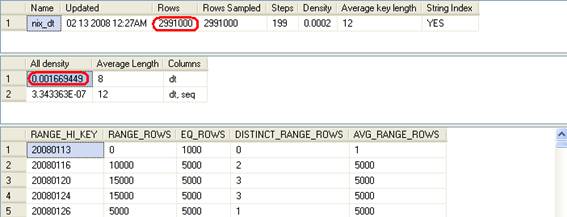
DBCC SHOW_STATISTICS ('dbo.test', 'nix_dt');
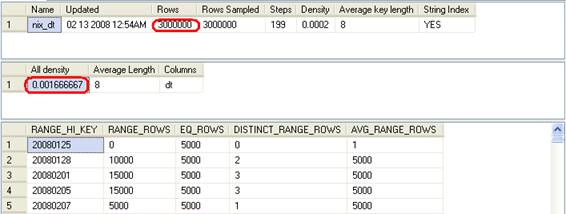
0.001666667*3000000 = 5000.001000000 가 예상 행 수가 된다는 것이다. 모든 날짜의 EQ_ROWS가 5000이므로 확인차 다음과 같이 데이터를 삭제 후 다시 계산해 보겠다.
sQL 6
delete from test
where seq <= 9000 and dt <= '20080113';
go
update statistics test
with fullscan
go
DBCC SHOW_STATISTICS ('dbo.test', 'nix_dt')
go
SQL 7
declare @dt char(8)
set @dt = '20080113'
select *
from test
where dt = @dt
--select 0.001669449*2991000
--4993.321959000
다음의
SQL8와 같이 인덱스를 사용하지 않도록 하여도 예상 행 수가 4993.32인 것을 보면 ‘=’ 비교의 경우는 Index Desity를 참조한다는 것을 확인 할 수 있다.
SQL 8
declare @dt char(8)
set @dt = '20080113'
select *
from test with (index = 0)
where dt = @dt
4 마무리 #
마지막으로 KB문서(
![[http]](/moniwiki/imgs/http.png) http://support.microsoft.com/kb/169642
http://support.microsoft.com/kb/169642)에 언급된 내용이 있다. 이 문서에 의하면 WHERE 조건에 WHERE dt like @dt + ‘%’와 같이 사용되면 Index Density를 실행계획을 세울 때 사용하지 않는다고 한다. 왜냐하면 로컬 변수를 사용한 Like 검색은 실행 시까지 그 분포를 알 수 없기 때문이다. 그럼 어떻게 이러한 Magic Density를 사용하지 않게 끔 하냐? 뭐.. 간단하다. ‘매개변수화’ 시키면 된다. SP만들거나 EXEC()써서 값을 직접 넣는 것처럼 만들거나 또는 sp_executesql을 쓰면 된다. (이런 내용이 왜 계속 업데이트 되어 뿌려지지 않는 건지 모르겠네요. 맨날 개노가다로 알아내야 하나요. 이런 제품 종속적인 공부 싫은데 말이죠..)
실행 시까지 분포를 알 수 없는 것은 SP를 작성 할 때도 마찬가지다. 잘못하면 실행계획의 재사용(Index Seek보다 Full Scan이 더 유리한 데이터 분포일 경우)으로 인해 악성SP가 될 수 있다. 이런 것을 요즘에는 ‘매개변수 스니핑’이라고 한다. 참 이름도 잘 갖다가 붙인다. 참고로 로컬 변수를 사용한 조건 WHERE dt like @dt + ‘%’에 대해 조금 테스트를 해보았는데 약 0.031% 정도가 예상 행 수가 되는 것을 확인했지만 좀 더 테스트를 해봐야 할 것 같다. 또한 like연산이 내부적으로 >, <, >=, <= 정도로 바뀌는데 이 역시 테스트 해보지는 않았다. 아직 확실한 공식은 찾아내지 못했다.



![[-]](/moniwiki/imgs/plugin/arrup.png "[-]")
![[+]](/moniwiki/imgs/plugin/arrdown.png "[+]")